近日,未来区块链与隐私计算高精尖创新中心团队在大语言模型领域的研究中取得新突破。团队提出一种基于分割学习的大语言模型分布式训练框架:FL-GLM,该框架首次引入分割学习用于大模型分布式训练,支持低GPU计算资源的客户端场景,只需运行少量显存的本地模型就可以参与到联邦大模型的训练中。
在竞争日趋激烈的“百模大战”中,如何获取海量的数据成为研发团队制胜的关键。目前大语言模型无法使用隐私数据进行训练,但隐私数据蕴含巨量的信息,如果能够用于训练大语言模型,将很大程度提升医疗、金融、政务等垂直领域的智能程度。针对该问题,团队提出的FL-GLM面向中英2个主流大模型——ChatGLM模型和Llama2模型,实现2种主流微调方法——P-tuning v2和Lora。实验结果验证FL-GLM框架在自然语言理解任务和自然语言生成任务上,任务指标不显著低于中心化训练方法,同时兼顾性能与数据安全。
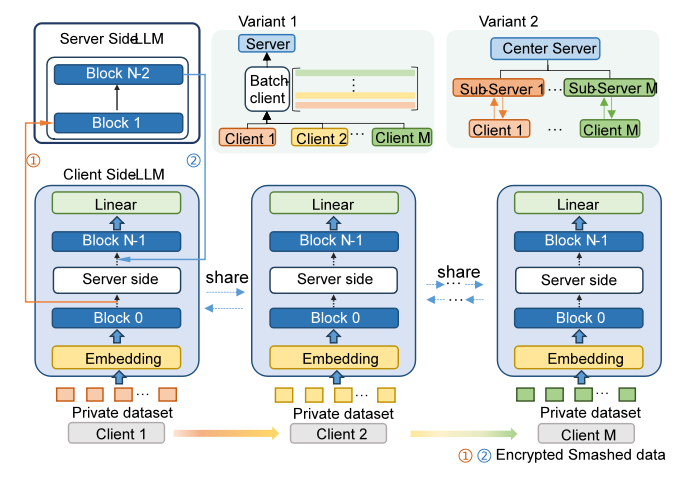
图 1 FL-GLM框架示意图
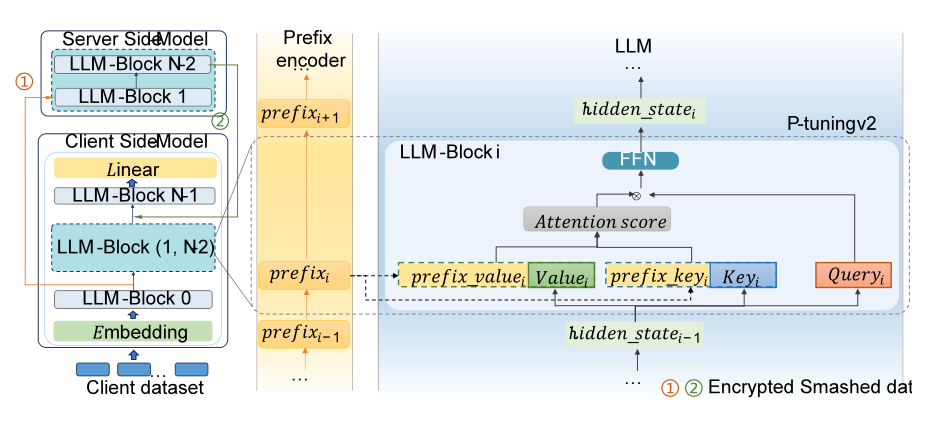
图 2 P-tuning v2 微调框架细节
该训练框架可面向各领域数据孤岛企业,如医院、金融机构等,这些数据孤岛企业可以利用各自持有的隐私数据训练垂直领域大型语言模型,在可信安全的机制下实现数据共享与使用,促进各领域数据价值的充分释放,为各个领域提供更安全的隐私数据模型训练方案。
未来区块链与隐私计算高精尖创新中心将深入学习贯彻落实党的二十大精神,对标北京市教委、学校对区块链与隐私计算领域科研成果产出的新要求,严把中心整体科研质量关,进一步提升中心在学术界的影响力和竞争力。




